I want to take the time today to demystify AI agents a bit.
I have no idea truly how useful this will be for you but this has been a useful way for me to think about AI agents and understand what they are and what's going on with them.
A lot of people think that AI agents are basically variants of the models we've been using, they think they are models with special brains that allow them to have more autonomy or act more independently.
This is actually not true. AI Agents are simply abstractions on top of existing foundational models.
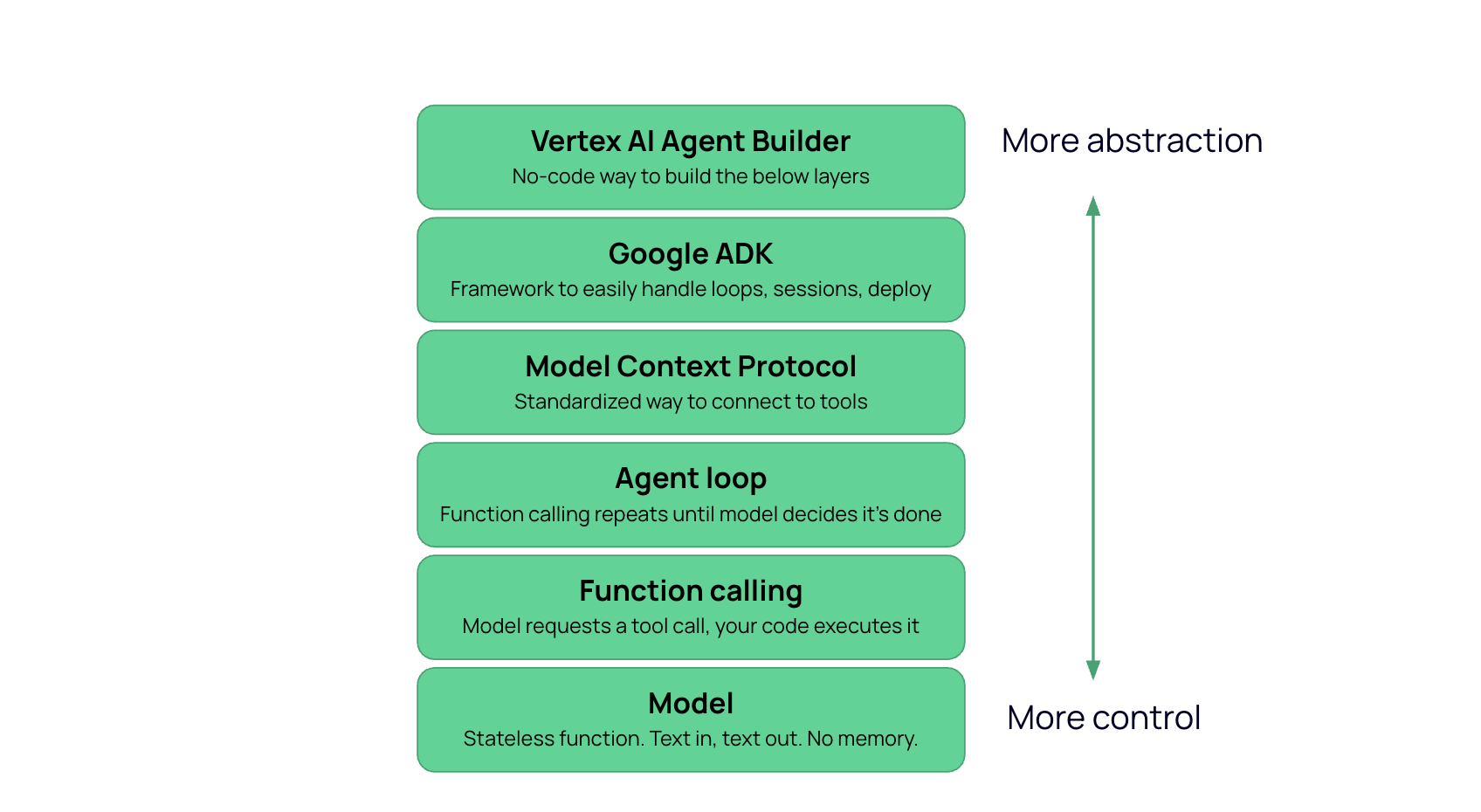
We can think of this as a stack.
At the bottom is the model. This would be Gemini, GPT, Claude, whatever you're using for your agent.
This model, as you may already know, works like a simple input-output system. You send it text, and it sends text back.
It is stateless. It doesn't actually have memory. It doesn't truly know what you sent it ten seconds ago. When you use these models in your browser, the reason it feels like a conversation, like it remembers you, is because the app on top of the model is re-sending the history of your conversation every time you send a new message. So then the model reads the whole thread fresh each time, and it can generate a new text output that is relevant to the new question you asked or message you sent and includes the previous messages you sent as well.
But the point is that the model alone is actually pretty bare bones. It can't do things in the real world, answer questions about your data, etc, because fundamentally it actually doesn't have access to more than just the input of your conversation.
So the question becomes: how do you get from a stateless text function to a system that uses tools and makes decisions?
This is where we introduce functions.
We can write code that acts as a tool for the model to use. And we can attach a description of that tool for the model to understand what it is and when to use it. These tools are called functions.
With these functions and their descriptions, the model will know "There's a function called query_sales_database that I can use with a SQL input string and get back rows with sales data." Or "There's a function called read_document that takes a file path and returns the text of that file."
The model still can't execute anything. It expresses intent through a function call request. Your code receives that intent, executes the function, and returns the result.
You might wonder how the model 'decides' which tool to use if all it does is generate text. The answer is that a function call request is still generated text. When function calling is enabled, the model's input includes descriptions of the available tools, and one valid form of output is a structured message that names a function and provides arguments. The model picks the function name and arguments the same way it generates any other output, by predicting the next tokens based on the input. Your code then parses that structured output and executes the function.
This solves the first problem. The model can now get information it wasn't given in the input, because it can request that your code go get it.
But there's a limitation. The model makes one request, gets one result, and produces a response. If answering the question requires two lookups, or three, or a lookup followed by a decision followed by another lookup, function calling alone doesn't handle that.
Instead of calling the model once, you call it in a loop.
Send the input, and if the model returns text, you are done. If the model returns a function call request, execute it, append the result to the conversation, and call the model again. Repeat until the model returns text.
That is the agent loop. There is no new capability in the model. The only addition is that your code keeps calling the same stateless function until it stops requesting tools. The model makes a decision, your code carries it out, the model sees the result and makes the next decision, and the loop continues until the model determines it has enough information to produce a final response.
The word "agent" refers to this loop. This is basically the layer where a model is converted into an agent, because it keeps going until it decides, through its reasoning capability, that it's done.
In function calling, you define each tool by hand. You write a Python function that queries BigQuery. You write another one that reads from Cloud Storage. Each one requires custom code and a custom description.
MCP replaces that per-tool custom work with a standard protocol. A BigQuery MCP server exposes its capabilities in a format any agent can discover and use. Your code still executes the calls, and the agent loop (if you are using one) is unchanged. What changes is how tools are defined and connected.
The practical consequence is that for any service that has an MCP server, you do not write the tool function. You connect to the server. For business logic specific to your application, you still write custom tools.
MCP is to tool connectivity what HTTP is to web communication. It is a protocol, not a capability. It standardizes the interface without changing what the model can or cannot do.
One thing to note is that although it is a higher layer of abstraction, this layer doesn't actually necessarily build on top of the agent loop. You can have an MCP without a loop, it just standardizes the communication between the model and the tools. But it is a higher level of abstraction.
Up to this point, you are writing everything yourself: the loop, the session management, the tool wiring, the web server, and the deployment config.
ADK packages the common parts. You declare an agent and hand it tools, and ADK provides the loop, manages conversation state, handles tool registration including MCP, and deploys to a managed runtime called Agent Engine. The model, tools, and loop logic are all the same. The difference is who writes the infrastructure code, you or the framework.
The tradeoff is direct. If ADK's default behavior matches what you need, it removes a lot of work. If you need the loop to behave differently (custom error handling, a specific approval flow, non-standard retry logic), you are either fighting the framework or going back to writing the loop yourself.
The final layer removes code entirely. You configure an agent through a UI, point it at data, select capabilities, and deploy. This replaces every layer below it. You do not write tools, you do not write a loop, and you do not choose a framework. The platform generates all of it.
The tradeoff is the same one that appears at every layer: more abstraction, less control.
You may however run into a situation where you need to elicit behavior from the model that the UI does not expose.
When you peer under the hood, AI Agents are not that complicated or scary.
Agents and agent-based systems are essentially abstractions on top of the models we are already familiar with.
In the agent stack, each layer takes something you were doing manually at the layer below and automates it.
Function calling automates external access and action-taking, the agent loop automates multi-step reasoning, MCP standardizes the connection, ADK provides an easy framework to do the boilerplate agent creation, and no-code tools like Agent Studio (formerly Agent Builder) put this all in a user friendly UI with no code.
At every layer, the tradeoff is the same: you gain speed/ease of use and you lose some control.

